
How to setup PySpark on Windows?
PySpark setup and Jupyter Notebook Integration
Apache Spark is an engine vastly used for big data processing. But why do we need it? Firstly, we have produced and consumed a huge amount of data within the past decade and a half. Secondly, we decided to process this data for decision-making and better predictions. Now as the amount of data grows, so does the need for infrastructure to process it efficiently and quickly (oh! The impatient homo-sapiens).
Apache Spark is an open-source engine and was released by the Apache Software Foundation in 2014 for handling and processing a humongous amount of data. Currently, Apache Spark provides high-level APIs in Java, Scala, Python, and R, and an optimized engine that supports general execution graphs. Spark also supports higher-level tools including Spark SQL for SQL and structured data processing, and MLlib for machine learning, to name a few.
Spark helps by separating the data in different clusters and parallelizing the data processing task for GBs and TBs of data. It does so at a very low latency, too. You can read further about the features and usage of Spark here.
But what is PySpark?
To put it in simple words, PySpark is a set of Spark APIs in Python language. It includes almost all Apache Spark features. Because of the simplicity of Python and the efficient processing of large datasets by Spark, PySpark became a hit among the data science practitioners who mostly like to work in Python.
What is wrong with “pip install pyspark” ?
Well, we (Python coders) love Python partly because of the rich libraries and easy one-step installation. In the case of PySpark, it is a bit different: you can still use the above-mentioned command, but your capabilities with it are limited. When using pip, you can install only the PySpark package which can be used to test your jobs locally or run your jobs on an existing cluster running with Yarn, Standalone, or Mesos. It does not contain features or libraries to set up your own cluster, which is a capability you want to have as a beginner.
If you want PySpark with all its features, including starting your own cluster, then follow this blog further…
PySpark Installation
Dependencies of PySpark for Windows system include:
- JAVA
- Python
- PySpark
- Winutils
1. Download and Install JAVA
As Spark uses Java Virtual Machine internally, it has a dependency on JAVA. Install the latest version of the JAVA from here.
- JAVA Download Link: here
- Install JAVA by running the downloaded file (easy and traditional browse…next…next…finish installation)
2. Download and Install Python
If you are going to work on a data science related project, I recommend you download Python and Jupyter Notebook together with the Anaconda Navigator.
- Anaconda Download Link: here
- Follow the self-explanatory traditional installation steps (same as above)
Otherwise, you can also download Python and Jupyter Notebook separately
- Python Download link: here
- Run the downloaded file for installation, make sure to check the “include python to Path” and install the recommended packages (including ‘pip’)
To see if Python was successfully installed and that Python is in the PATH environment variable, go to the command prompt and type “python”. You should see something like this. (my Python version is 3.8.5, yours could be different)

In case you do not see the above command, please follow this tutorial for help.
Next, you will need the Jupyter Notebook to be installed for learning integration with PySpark
Install Jupyter Notebook by typing the following command on the command prompt: “pip install notebook”
3. Download and unzip PySpark
Finally, it is time to get PySpark. From the link provided below, download the .tgz file using bullet point 3. You can choose the version from the drop-down menus. Then download the 7-zip or any other extractor and extract the downloaded PySpark file. Remember, you will have to unzip the file twice.

Note: The location of my file where I extracted Pyspark is
“E:\PySpark\spark-3.2.1-bin-hadoop3.2” (we will need it later)
4. Download winutils.exe
In order to run Apache Spark locally, winutils.exe is required in the Windows Operating system. This is because Spark needs elements of the Hadoop codebase called ‘winutils‘ when it runs on non-windows clusters. These windows utilities (winutils) help the management of the POSIX(Portable Operating System Interface) file system permissions that the HDFS (Hadoop Distributed File System) requires from the local (windows) file system.
Too-technical? Just download it. Make sure to select the correct Hadoop version.
- winutils.exe Download Link: here
- Create a folder structure hadoop\bin within the Pyspark folder and put the downloaded winutils.exe file there.

Note: The location of my winutils.exe is
“E:\PySpark\spark-3.2.1-bin-hadoop3.2\hadoop\bin”
5. Set Environment variables
Now that we have downloaded everything we need, it is time to make it accessible through the command prompt by setting the environment variables.
Some Side Info: What are Environment variables?
Environment variables are global system variables accessible by all the processes / users running under the operating system.
PATH is the most frequently used environment variable, it stores a list of directories to search for executable programs (.exe files). To reference a variable in Windows, you can use
%varname%.Some more side info: What does PATH do?
When you launch an executable program (with file extension of "
.exe", ".bat" or ".com") from the command prompt, Windows searches for the executable program in the current working directory, followed by all the directories listed in thePATHenvironment variable. If the program is not found in these directories, you will get the following error saying “the command is not recognized”.
Back to the PySpark installation. In order to set the environment variables
- Go to Windows search
- Type “env” —it will show the “edit environment variable for your account”, click on it
- Click on “New” for the user variables and add the following variable name and values (depending upon the location of the downloaded files)


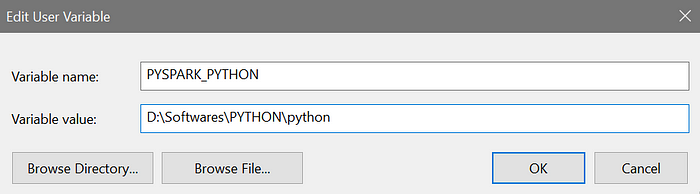
Next, Update the PATH variable with the \bin folder address, containing the executable files of PySpark and Hadoop. This will help in executing Pyspark from the command prompt.
- Click on the “Path” variable

- Then add the following two values ( we are using the previously defined Environment variables here)
%SPARK_HOME%\bin
%HADOOP_HOME%\bin

6. Let's fire PySpark!
Test if PySpark has been installed correctly and all the environment variables are set.
- Go to command prompt
- type “pyspark”

Great! You have now installed PySpark successfully and it seems like it is running. To see PySpark running, go to “https://localhost:4040” without closing the command prompt and check for yourself.

7. Jupyter Notebook integration with Python
Now, once the PySpark is running in the background, you could open a Jupyter notebook and start working on it. But running PySpark commands will still throw an error (as it does not know which cluster to use) and in that case, you will have to use a python library “findspark”. And use the following two commands before PySpark import statements in the Jupyter Notebook.
import findspark
findspark.init()But there is a workaround. You can configure PySpark to fire up a Jupyter Notebook instantiated with the current Spark cluster by running just the command “pyspark” on the command prompt. To achieve this, you will not have to download additional libraries. For this…
… you will need to add two more environment variables


Now, when you run the “pyspark” in the command prompt:
- It will give information on how to open the Jupyter Notebook.
- Just copy the URL (highlight and use CTRL+c) and paste it into the browser along with the token information — this will open Jupyter Notebook.

8. Running a sample code on the Jupyter Notebook
Just to make sure everything is working fine, and you are ready to use the PySpark integrated with your Jupyter Notebook.
- Run Pyspark through the command prompt
- Open Jupyter Notebook
- Write the following commands and execute them
# Import Libraries
import pyspark
from pyspark import SQLContext
# Setup the Configuration
conf = pyspark.SparkConf()
spark_context = SparkSession.builder.getOrCreate()
# Add Data
data = ([(1580, "John", "Doe", "Mars" ),
(5820, "Jane", "Doe", "Venus"),
(2340, "Kid1", "Doe", "Jupyter"),
(7860, "Kid2", "Doe", "Saturn")
])
# Setup the Data Frame
user_data_df = spark_context.createDataFrame(data)
# Display the Data Frame
user_data_df.show()
- Open the URL https://localhost:4040 and check for yourself.

My Version information
- Python: 3.8.5
- JAVA: 1.8.0_331
Java™ SE Runtime Environment (build 1.8.0_331-b09)
Java HotSpot™ 64-Bit Server VM (build 25.331-b09, mixed mode) - PySpark: 3.2.1 (spark-3.2.1-bin-hadoop3.2.tgz)
- Hadoop winutils.exe: 3.2.1
- Jupyter:
IPython : 7.30.1
ipykernel : 6.6.0
jupyter_client : 7.0.6
jupyter_core : 4.9.1
notebook : 6.4.6
CONGRATULATIONS! You were able to set up the environment for PySpark on your Windows machine.
Please write in the comment section if you face any issues.
